A Deep Dive on Hadoop Core Components and Ecosystem

Welcome to this comprehensive guide covering various Hadoop technologies. Use the index below to quickly navigate to the topics that interest you.
Index
Apache Hadoop
Apache Hadoop is an open-source framework designed for distributed storage and processing of large datasets across clusters of computers. It was originally developed by Doug Cutting and Mike Cafarella and is now maintained by the Apache Software Foundation.
Core Components of Hadoop
Hadoop Common
Hadoop Common serves as the foundation of the Hadoop ecosystem. It includes a set of essential libraries, utilities, and necessary resources that support the functionality of other Hadoop modules, such as HDFS, MapReduce, and YARN. This ensures that all modules within the Hadoop ecosystem can work seamlessly together.
Key components of Hadoop Common:
- Core Libraries: These libraries provide the fundamental functions for writing and executing Hadoop applications.
- Java Archive (JAR) Files: Hadoop Common houses JAR files required to start Hadoop services and facilitates interaction between different Hadoop modules.
- File System Abstraction: It includes the interfaces and support for Hadoop’s file system, ensuring compatibility with a variety of storage systems.
- Authentication & Security Features: Hadoop Common incorporates features like Kerberos for authentication, ensuring secure access to data.
- Configuration Management: It manages and provides configuration files needed for the proper functioning of the Hadoop ecosystem.
- Native Libraries: It includes native Java libraries that enhance performance by enabling faster processing and efficient storage.
Hadoop Common plays a pivotal role in providing the shared infrastructure, ensuring that the Hadoop ecosystem operates as an integrated and cohesive platform. Without Hadoop Common, the individual modules would not have a unified framework to communicate and function effectively.
Hadoop Distributed File System (HDFS)
HDFS is a distributed file system designed to store and manage large amounts of data efficiently across multiple machines. It provides high-throughput access to application data in the Hadoop ecosystem.
Key Features
- Block Storage: HDFS divides data into fixed-size blocks, typically 128 MB or 256 MB, and distributes them across multiple nodes in a cluster. This enables parallel processing and increases the system’s fault tolerance.
- Replication: Each data block is replicated multiple times (default is three copies) across different nodes. This ensures high availability and fault tolerance by providing redundancy; if one node fails, the data can still be accessed from another node.
- Scalability: HDFS is designed to scale horizontally. As the volume of data increases, new nodes can be added to the cluster without downtime, enabling seamless growth.
- High Throughput: HDFS is optimized for high-throughput data access rather than low-latency access. It is well-suited for large-scale data processing tasks that require reading and writing large files.
- Fault Tolerance: By replicating data blocks and continuously monitoring the health of nodes, HDFS ensures data integrity and availability even in the event of hardware failures.
- Data Locality: HDFS takes advantage of data locality by trying to place computation close to where the data resides. This reduces network congestion and improves processing speed.
Architecture
- NameNode: The NameNode is the master server that manages the metadata and file system namespace. It keeps track of the locations of data blocks and their replicas.
- DataNodes: DataNodes are the worker nodes that store the actual data blocks. They periodically report the status and health of the blocks to the NameNode.
- Secondary NameNode: The Secondary NameNode is a helper node that periodically creates checkpoints of the HDFS metadata to prevent data loss in case of NameNode failure.
Hadoop YARN (Yet Another Resource Negotiator)
YARN acts as the resource management layer for the Hadoop ecosystem. It enables applications to access and share computational resources efficiently across the cluster. Essentially, YARN separates job scheduling and resource management, making Hadoop more flexible and scalable for diverse use cases.
Key roles of YARN in the Hadoop ecosystem:
- Resource Management: YARN dynamically allocates resources (CPU, memory, etc.) to applications running in the Hadoop cluster.
- Job Scheduling: It schedules tasks and monitors their execution to ensure efficient use of resources.
- Support for Diverse Frameworks: Unlike the original Hadoop model that primarily supported MapReduce, YARN is framework-agnostic, allowing other processing frameworks like Apache Spark, Tez, and Flink to run on Hadoop.
To summarize, YARN falls under Hadoop’s core framework, as it underpins the entire ecosystem’s ability to execute and manage various workloads in a distributed environment. It complements HDFS and enables the modular scalability of Hadoop.
Hadoop MapReduce
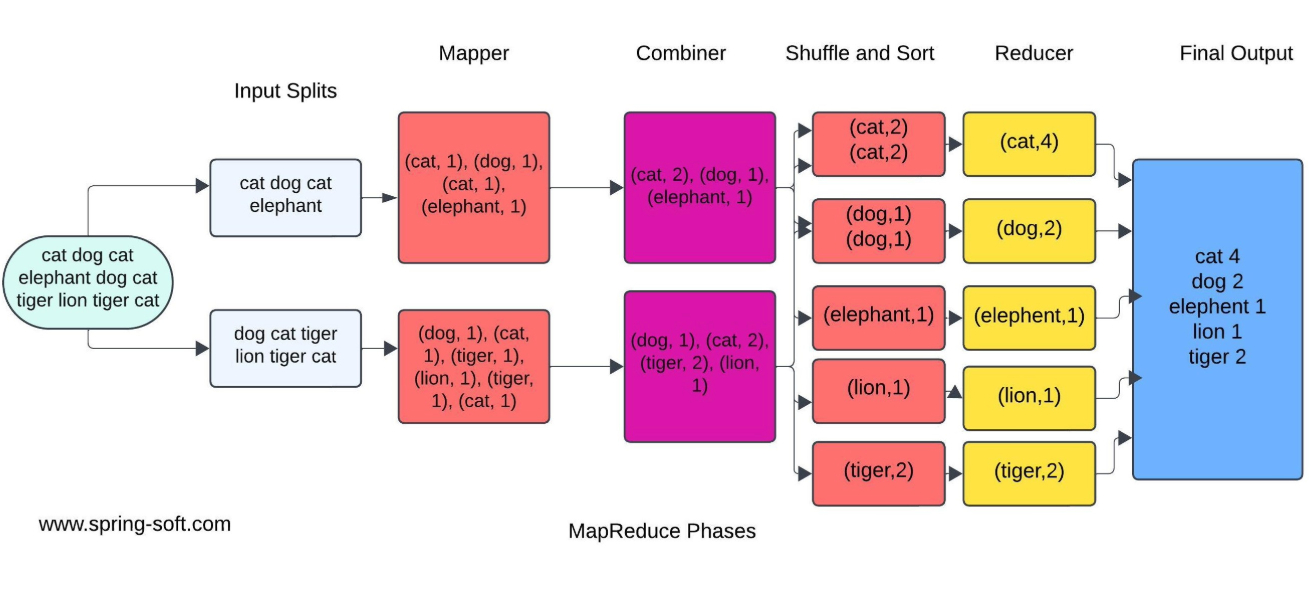
MapReduce is a programming model and processing engine for large-scale data processing. It allows users to write programs that can process vast amounts of data in parallel. The processing is divided into several phases:
Processing Phases
- Map Phase
- Processes input data and generates intermediate key-value pairs.
- Combiner Phase (optional)
- Acts as a mini-reducer, processing intermediate key-value pairs to combine them locally before the shuffle and sort phase. This helps reduce the amount of data transferred to the Reducer.
- Partitioner Phase
- Determines how the intermediate key-value pairs are distributed to the Reducer nodes. It ensures that all records with the same key end up on the same Reducer.
- Shuffle and Sort Phase
- Transfers intermediate key-value pairs from the Mapper to the Reducer nodes and sorts them by key.
- Reduce Phase
- Aggregates and processes the intermediate key-value pairs to produce the final output.
Efficiency Enhancements
The inclusion of the Partitioner and Combiner phases enhances the efficiency of MapReduce by optimizing data transfer and reducing computation time.
How HDFS, YARN, and MapReduce Work Together
-
Data Storage:
HDFS serves as the foundation by storing the data to be processed by MapReduce. The data is divided into blocks and distributed across multiple nodes in the cluster to ensure scalability and reliability. -
Job Submission:
Users submit MapReduce jobs to the YARN ResourceManager, specifying the input data (stored in HDFS) and the MapReduce program to execute. -
Resource Allocation:
The ResourceManager allocates the necessary resources for the job by coordinating with NodeManagers across the cluster. This ensures optimal resource utilization and task distribution. -
Data Locality:
YARN leverages HDFS’s data locality feature to schedule MapReduce tasks as close to the data’s physical location as possible. This minimizes data transfer overhead and accelerates processing. -
MapReduce Execution:
The MapReduce framework processes the data stored in HDFS via mappers and reducers, generating intermediate and final results. These results are often written back to HDFS for storage or further analysis.
Hadoop Ecosystem
Hadoop is not just limited to its core components; it also includes a rich ecosystem of tools and technologies that enhance its capabilities:
Apache ZooKeeper
Apache ZooKeeper is an open-source, distributed coordination service designed to manage and coordinate large-scale distributed systems. It provides a centralized infrastructure for maintaining configuration information, naming, distributed synchronization, and group services. ZooKeeper is a critical component for ensuring the reliability and stability of distributed applications.
Key Features of Apache ZooKeeper
- Coordination and Synchronization: ZooKeeper offers primitives like distributed locks, barriers, and queues to coordinate processes effectively. This ensures multiple processes can collaborate smoothly.
- Consistency and Reliability: ZooKeeper maintains a consistent system state across all nodes using a hierarchical namespace, akin to a filesystem, to store and manage configuration data for easy retrieval and updates.
- High Availability: ZooKeeper is designed to be fault-tolerant and highly available. It employs an ensemble of servers (typically an odd number) to form a quorum, ensuring the service remains functional even when servers fail.
- Watch Mechanism: ZooKeeper enables clients to receive notifications of data changes, allowing the creation of reactive systems that respond to modifications in real time.
Use Cases of Apache ZooKeeper
- Configuration Management: It serves as a centralized repository for storing and synchronizing configuration settings, guaranteeing consistency across nodes in distributed systems.
- Leader Election: ZooKeeper ensures reliable leader election for distributed systems, enabling one node to coordinate tasks at any given moment.
- Naming Service: It functions as a naming service, assigning unique names to resources for seamless resource discovery and management.
- Distributed Locks: ZooKeeper’s distributed locks prevent conflicts by ensuring only one process accesses a resource simultaneously, preserving data integrity.
- Service Discovery: It aids in dynamic service discovery, allowing clients to locate and connect to services within a distributed system.
Apache Pig
Apache Pig is a high-level platform designed for analyzing large datasets. It comprises a high-level language for expressing data analysis programs, known as Pig Latin, along with an infrastructure for evaluating these programs. Pig’s structure facilitates substantial parallelization, making it highly effective for handling very large datasets.
Infrastructure Layer
Pig’s infrastructure layer is built on a robust foundation that utilizes a compiler to convert Pig Latin scripts into sequences of MapReduce programs. By leveraging Hadoop’s powerful distributed processing capabilities, Pig ensures high scalability and efficiency for large-scale data processing tasks.
Pig Latin Language
Pig Latin, the heart of Apache Pig, offers several standout features:
- Ease of Use: Pig Latin offers a simpler syntax compared to Java-based MapReduce programs, making it more accessible to data engineers and analysts.
- Extensibility: Pig supports custom functions written in Java, Python, or other languages, allowing users to extend its capabilities as needed.
- Optimized Execution: Pig’s execution engine automatically optimizes the processing pipeline, improving efficiency.
- Schema Flexibility: It handles semi-structured and unstructured data with ease, enabling complex data transformations.
Apache Hive
Facebook developed Hive in 2007 to manage and analyze the vast amounts of data generated by its users. The goal was to create a system capable of handling petabytes of data while providing a SQL-like interface for querying and managing this data. Hive was later open-sourced and became a part of the Apache Hadoop ecosystem.
Hive and MapReduce
Hive translates SQL-like queries into MapReduce jobs that run on Hadoop. This allows users to write queries in a familiar SQL-like language while leveraging Hadoop’s distributed computing framework. Here’s how it works:
- Query Execution: Hive converts submitted queries into a directed acyclic graph (DAG) of MapReduce jobs.
- Map Phase: The MapReduce jobs process the input data and generate intermediate key-value pairs.
- Reduce Phase: The intermediate key-value pairs are aggregated and processed to produce the final output.
Hive Internals
Hive’s architecture consists of several key components:
- Metastore: Stores metadata about tables, columns, partitions, and data types.
- Driver: Manages the lifecycle of a HiveQL statement, including query compilation, optimization, and execution.
- Compiler: Converts HiveQL statements into a DAG of MapReduce jobs.
- Execution Engine: Executes the DAG of MapReduce jobs on the Hadoop cluster.
External Tables
Hive supports two types of tables: Managed (Internal) and External:
- Managed Tables: Hive manages both the metadata and the data. Dropping a managed table deletes both the metadata and the data.
- External Tables: Hive only manages the metadata, while the data is stored externally. Dropping an external table deletes the metadata but retains the data, making external tables ideal for sharing data between Hive and other tools or when storing data outside Hive.
In summary, Apache Hive remains a cornerstone of the Hadoop ecosystem, offering a powerful SQL-like interface for processing and analyzing vast datasets. It is particularly well-suited for use cases such as log analysis, ETL processes, and ad-hoc querying in data warehousing environments, where its ability to simplify complex data tasks shines.
While Hive excels in enabling users to leverage Hadoop’s distributed computing power without needing extensive programming knowledge, it differs from tools like Apache Pig, which is more script-oriented, or Spark SQL, which provides faster processing for interactive analytics. However, Hive’s reliance on MapReduce introduces latency, making it less ideal for real-time or low-latency query requirements. This limitation has spurred the adoption of newer frameworks like Apache Impala and Presto, which offer faster query execution. As data processing continues to evolve, Hive’s role remains pivotal, complemented by these emerging tools that address its shortcomings.
Apache Sqoop
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured data stores such as relational databases. It provides a simple command-line interface for importing and exporting data, enabling seamless integration between Hadoop and various databases.
One of Sqoop’s key features is its ability to create MapReduce jobs behind the scenes to perform data transfer. This ensures that the processes for importing and exporting data are distributed, fault-tolerant, and scalable. By leveraging Hadoop’s processing power, Sqoop efficiently handles large volumes of data.
Sqoop supports a variety of databases, including MySQL, PostgreSQL, Oracle, SQL Server, and more. It can import entire tables or specific subsets of data and also offers options for incremental imports, allowing users to capture only data changes since the last import.
Use Cases of Apache Sqoop
- Data Ingestion for Hadoop: Sqoop is widely used to import data from relational databases into Hadoop’s HDFS, where it can be further processed and analyzed using tools like Hive, Pig, or Spark.
- ETL Processes: Sqoop plays a critical role in ETL (Extract, Transform, Load) workflows by transferring data efficiently between Hadoop and external data stores. This allows organizations to perform complex data transformations and analytics using Hadoop.
- Data Export: It enables the export of processed data from Hadoop back into relational databases, making it readily available for business intelligence, reporting, and other downstream applications.
- Data Warehousing: Sqoop facilitates Hadoop’s integration with traditional data warehouses, combining the strengths of both systems for comprehensive data analysis.
Overall, Apache Sqoop serves as a powerful bridge between Hadoop and structured data stores, making data transfer and integration seamless across a wide range of use cases.
Apache HBase
Apache HBase is a columnar database in the Hadoop ecosystem that specializes in handling large datasets efficiently.
Columnar Property
HBase is a column-family-oriented database, meaning it organizes data in columns rather than rows. Columns are grouped into column families, with each family containing multiple columns. This columnar structure optimizes storage and retrieval processes, making HBase particularly well-suited for read-heavy workloads and efficient query execution.
Multi-Valued Property
HBase supports multi-valued properties by allowing multiple versions of a value to be stored in a single cell. Each cell is uniquely identified by a combination of row key, column family, column qualifier, and timestamp. This feature is invaluable for maintaining historical data records, supporting use cases like auditing, versioning, and time-series data analysis.
Use Cases of HBase
- Real-Time Analytics: Enables analysis of user behavior, sensor data, and financial transactions in real-time.
- Time-Series Data: Ideal for storing and analyzing time-series datasets, such as IoT data, stock market trends, and performance metrics.
- Content Management: Handles large volumes of unstructured or semi-structured data, making it suitable for storing logs, social media posts, and user-generated content.
- Data Warehousing: Acts as a backend for data warehousing solutions, providing fast read/write operations for reporting and data aggregation.
Efficient Read/Write for Real-Time Response
- Write Operations: Utilizes an in-memory write buffer (MemStore) and on-disk storage (HFiles) for efficient write operations, reducing latency.
- Read Operations: Employs BlockCache for caching frequently accessed data and Bloom filters to quickly verify row existence in store files, optimizing read performance.
- Compaction: Merges smaller HFiles into larger ones during automatic compaction processes, enhancing read efficiency and overall system performance.
HBase’s columnar and multi-valued properties, combined with its efficient read/write mechanisms, establish it as a powerful database solution for real-time analytics, time-series data, content management, and data warehousing.
Apache Flume
Apache Flume is a distributed, reliable, and available service designed for efficiently collecting, aggregating, and transporting large amounts of log data from various sources to a centralized data store. Flume is built to handle high throughput and is highly customizable, making it an essential tool for log data management in big data environments.
Key Features of Apache Flume
- Reliable and Scalable: Flume is designed to handle high-volume data flows with fault-tolerant capabilities. It supports horizontal scalability by adding more agents to increase capacity.
- Flexible Architecture: Its architecture is modular, consisting of sources, channels, and sinks. Each component can be customized or extended to suit specific requirements.
- Multiple Sources and Sinks: Flume supports a wide variety of data sources, including log files, syslog, and HTTP streams, and can send data to multiple sinks such as HDFS, HBase, and Solr, making it highly versatile for different ingestion and storage needs.
- Stream Processing: Flume processes data in real-time as it flows through the system, allowing for immediate analysis and transformation of log data before reaching its final destination.
Use Cases of Apache Flume
- Log Data Aggregation: Collects log data from distributed systems, like web servers, application servers, and network devices, and aggregates it into centralized stores for monitoring and analysis.
- Real-Time Analytics: Enables real-time streaming of log data for analytics and monitoring, providing organizations the ability to promptly detect and resolve issues.
- Data Ingestion for Hadoop: Facilitates the ingestion of log data into Hadoop ecosystems, such as HDFS or HBase, for further processing and analytics using tools like MapReduce, Hive, and Spark.
- Security and Compliance: Aggregates and centralizes log data to aid in monitoring, auditing, and analyzing logs for detecting suspicious activities or ensuring compliance with regulatory standards.
Apache Spark
Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It builds upon Hadoop’s MapReduce concept, enhancing and optimizing it to provide a more efficient and user-friendly framework.
Optimized from Hadoop MapReduce
Spark improves upon Hadoop MapReduce by implementing advanced optimizations. Unlike MapReduce, which writes intermediate data to disk, Spark operates primarily in memory, enabling faster processing times and more efficient data handling.
Spark RDD and In-Memory Computation
At the core of Spark is the Resilient Distributed Dataset (RDD), a fault-tolerant collection of objects that can be processed in parallel across a cluster. RDDs support two primary types of operations:
- Transformations: Operations such as map, filter, and join.
- Actions: Operations such as count, collect, and save.
Spark’s in-memory computation capabilities allow it to process data significantly faster than traditional disk-based frameworks.
Use Cases of Apache Spark
- Batch Processing: Spark excels in batch processing tasks, such as ETL (Extract, Transform, Load) jobs and data aggregation.
- Stream Processing: With Spark Streaming, it can process real-time data streams, making it ideal for applications like real-time analytics, monitoring, and event detection.
- Machine Learning: The MLlib library provides scalable algorithms for classification, regression, clustering, and collaborative filtering, allowing developers to build and deploy machine learning models.
- Graph Processing: Spark GraphX enables distributed analysis of large-scale graphs, such as social networks and recommendation engines.
- Interactive Data Analysis: Its rich APIs and integration with tools like Jupyter Notebooks make Spark a powerful tool for interactive data exploration and visualization.
Learn more about Apache Spark : Apache Spark: The Game-Changer in Big Data Analytics
In conclusion, the Hadoop ecosystem, with its core components and rich array of complementary tools, is a testament to the power and flexibility of distributed computing for managing and analyzing massive datasets. From the foundational integration of HDFS, YARN, and MapReduce to the diverse ecosystem tools like Hive, Pig, Spark, and beyond, Hadoop offers a robust framework tailored to a wide range of big data use cases. Each component and tool contributes uniquely—whether it’s enabling real-time analytics, simplifying data ingestion, or scaling storage and processing capabilities. As big data continues to evolve, so does Hadoop, providing the backbone for innovative solutions in data management and analytics. This deep dive sheds light on the intricate workings and collaboration within the ecosystem, laying the groundwork for readers to harness its full potential.
Author: Mohammad J Iqbal
