Apache Spark: The Game-Changer in Big Data Analytics
Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It builds upon Hadoop’s MapReduce concept, enhancing and optimizing it to provide a more efficient and user-friendly framework.
How Spark differ from Hadoop MapReduce?
Spark improves upon Hadoop MapReduce by implementing advanced optimizations. Unlike MapReduce, which writes intermediate data to disk, Spark operates primarily in memory, enabling faster processing times and more efficient data handling.
Spark RDD and In-Memory Computation
Resilient Distributed Dataset (RDD), a fault-tolerant collection of objects that can be processed in parallel across a cluster, ensuring scalability. RDDs are immutable, meaning their structure cannot be altered once created.
RDDs support two primary types of operations:
- Transformations: Operations such as map, filter, and join, create new RDDs by defining data processing logic.
- Actions: Operations such as count, collect, and save, trigger the execution of transformations and return results or write data to storage.
Spark’s in-memory computation capabilities allow it to process data significantly faster than traditional disk-based frameworks.

Fault Tolerance: One of the standout features of RDDs is their fault tolerance. They achieve this by maintaining lineage information, which allows them to rebuild lost partitions automatically in the event of node failures. This ensures reliability without relying on costly data replication.
In-Memory Computation: Another key advantage of RDDs is their ability to perform computations in memory. By minimizing reliance on disk-based processing, Spark achieves significantly faster data processing speeds compared to traditional frameworks.
The combination of parallel processing, in-memory computation, and fault tolerance makes RDDs a powerful and flexible solution for handling large-scale data processing tasks in Spark.
Use Cases of Apache Spark
- Batch Processing: Spark excels in batch processing tasks, such as ETL (Extract, Transform, Load) jobs and data aggregation.
- Stream Processing: With Spark Streaming, it can process real-time data streams, making it ideal for applications like real-time analytics, monitoring, and event detection.
- Machine Learning: The MLlib library provides scalable algorithms for classification, regression, clustering, and collaborative filtering, allowing developers to build and deploy machine learning models.
- Graph Processing: Spark GraphX enables distributed analysis of large-scale graphs, such as social networks and recommendation engines.
- Interactive Data Analysis: Its rich APIs and integration with tools like Jupyter Notebooks make Spark a powerful tool for interactive data exploration and visualization.
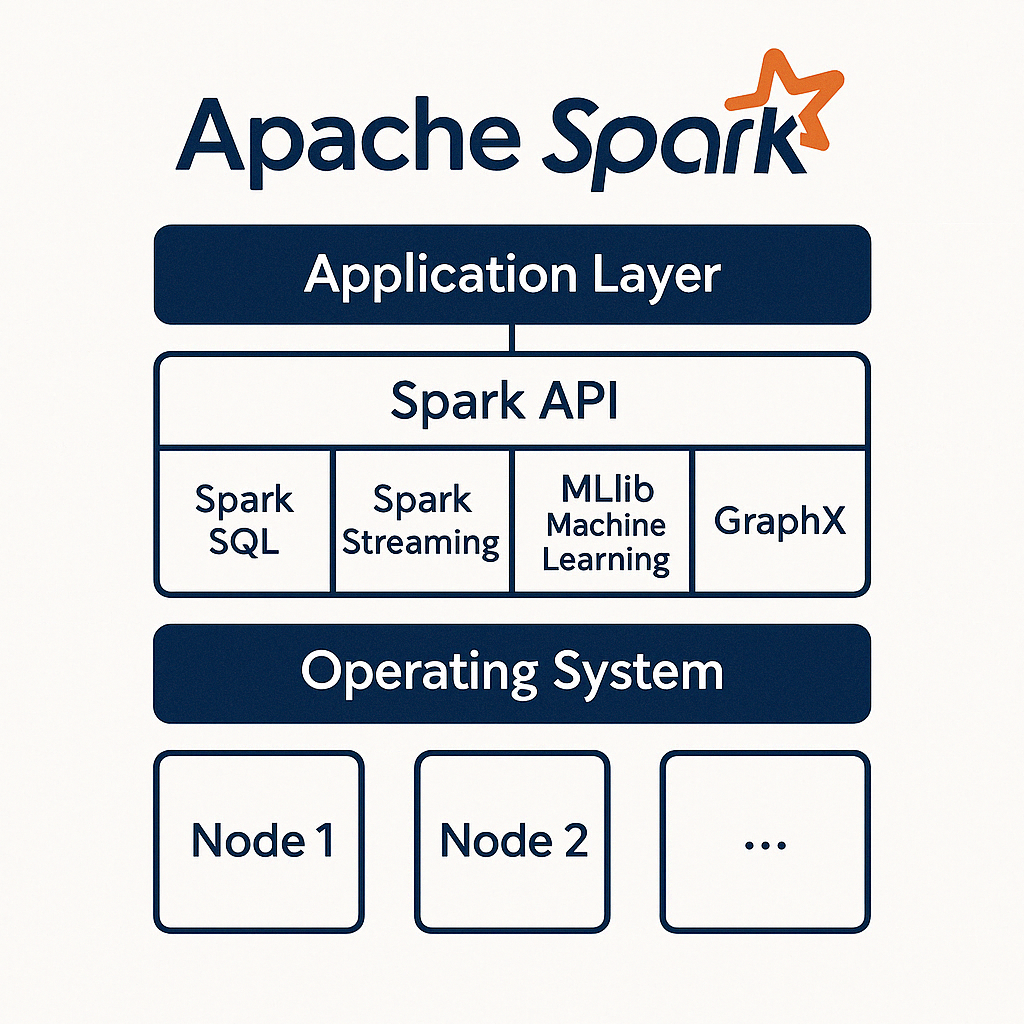
Spark APIs
Apache Spark offers a rich set of APIs tailored for diverse data processing and analytics needs. Each API serves a specialized purpose, making Spark an adaptable solution across industries:
- Spark SQL: Provides SQL-like query capabilities for structured and semi-structured data. It enables seamless integration with existing BI tools and supports both batch and interactive querying.
- Spark Streaming: Allows real-time data processing of streams, making it ideal for applications like event detection, monitoring, and live dashboards.
- MLlib (Machine Learning Library): Offers scalable machine learning algorithms for regression, classification, clustering, and recommendation systems. It simplifies the development and deployment of machine learning models at scale.
- GraphX: A graph processing framework for distributed analysis of large-scale graphs, such as social networks and recommendation systems.
Author: Mohammad J Iqbal
