Spark Architecture: The Backbone of Distributed Computing
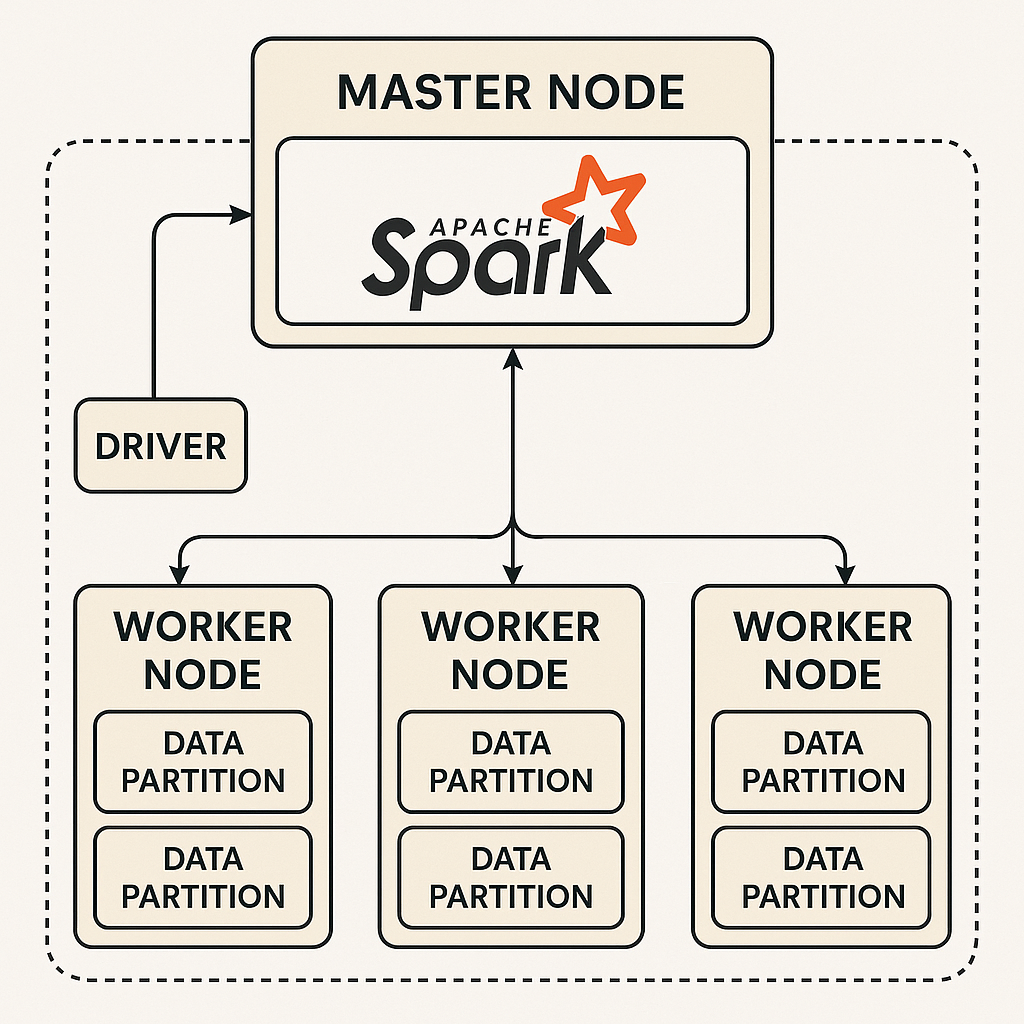
Components of Spark Architecture
- Driver: The heart of a Spark application, responsible for orchestrating execution. It splits the code into tasks and sends them to workers.
- Initiates the Spark application and coordinates the cluster tasks.
- Sends tasks to the master node for scheduling and monitors their execution.
- Handles communication with executors.
- Cluster Manager: Coordinates resources across nodes in the cluster. Spark supports managers like Standalone, Apache Mesos, and Hadoop YARN.
- Workers: Nodes that execute tasks. Each worker has its own executors and works on a subset of the data partitions.
- Executors: Run the actual tasks assigned by the driver. Executors also store processed data and act as communication endpoints for the driver.
Master and Worker Nodes
- Master Node:
- Central point for resource management and task scheduling.
- Assigns tasks received from the driver to appropriate worker nodes.
- Worker Nodes:
- Execute the tasks assigned by the master node.
- Store data partitions and process data locally.
- Communicate with the driver during execution.
For every Spark application, the first operation is to connect to the Spark master and get a Spark session. This is an operation you will do every time.
For an example, look at the code below. In this context, you are connecting to Spark in local mode.
//Getting a Spark session
SparkSession spark = SparkSession.builder()
.appName("CSV to DB")
.master("local")
.getOrCreate();
Data Partitions and Parallelism:
Spark’s data partitioning enables parallel processing by dividing large datasets into smaller partitions distributed across worker nodes. Each partition is processed independently, enhancing scalability and fault tolerance. Proper partitioning minimizes overhead and optimizes resource use, boosting performance. To achieve this, aim for partition sizes of 128 MB to 1 GB and align the number of partitions with your cluster’s cores. Additionally, prioritize data locality to reduce network overhead and improve processing efficiency. Partition tuning ensures Spark handles big data effectively.
Spark’s Memory Model
Spark’s memory model is designed to balance in-memory computation and disk-based storage. It utilizes techniques like caching and persistence levels to store intermediate results in memory, reducing repeated computations and improving performance. Tasks such as shuffle operations rely on effective memory management to prevent excessive data spilling to disk, which can impact processing speed. By optimizing memory allocation and minimizing disk I/O, Spark ensures efficient and scalable data processing across clusters.
Spark Data Ingestion
Data ingestion enables parallel processing by dividing datasets and distributing tasks across multiple worker nodes. In the diagram below, we illustrate how Spark ingests data from a CSV file, organizes it into memory partitions, and activates relevant tasks to process the data efficiently.
CSV File Data
Record,FirstName,LastName
Record1,John,Doe
Record2,Jane,Smith
Record3,Michael,Brown
Record4,Emily,Davis
Record5,David,Johnson
Record6,Sarah,Wilson
Record7,Chris,Anderson
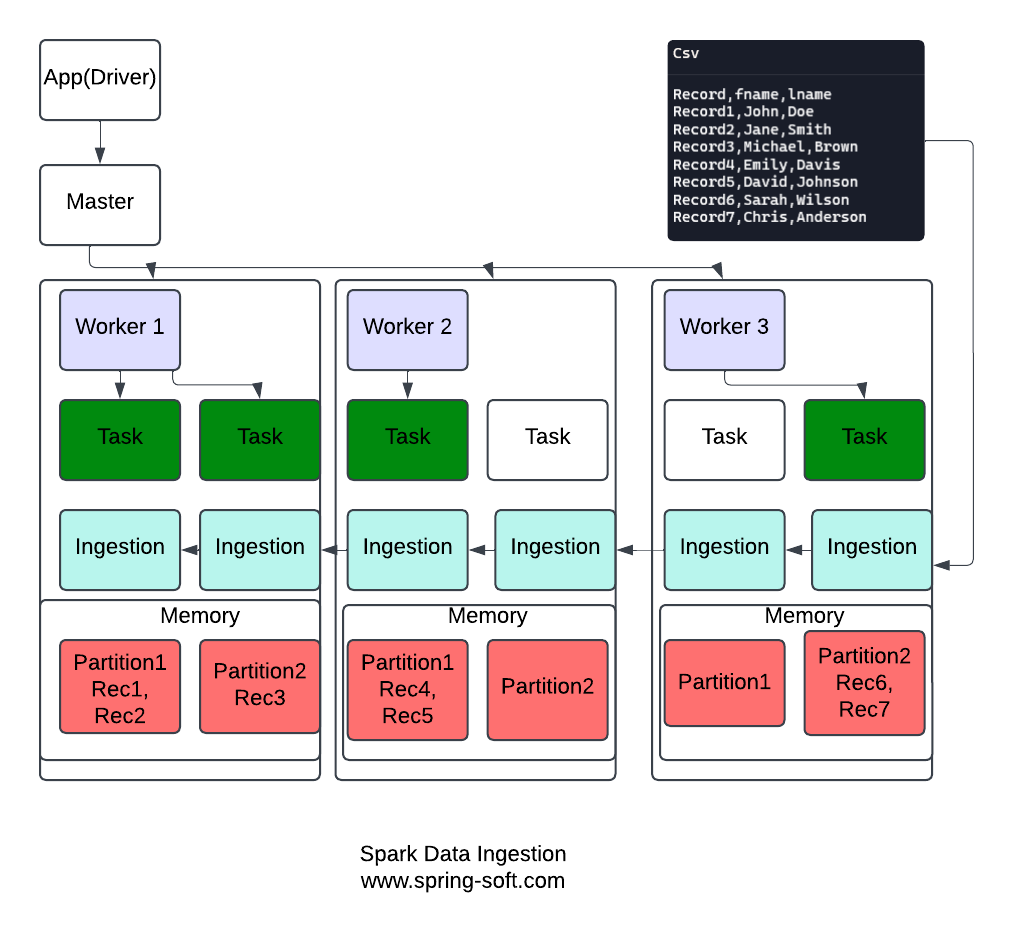
Key Components and Process Overview for Spark Data Ingestion:
Workers and Executors
- There are three worker nodes: Worker1, Worker2, and Worker3.
- Each worker node hosts two executors, which are responsible for executing tasks assigned by the Spark driver. Executors act as the computational units of Spark’s architecture.
Memory Partitions
- Every worker node is equipped with its own memory, which is subdivided into two partitions: Partition1 and Partition2.
- Partitions are logical divisions within memory where data is stored. This division facilitates parallel processing, allowing Spark to handle chunks of data independently.
Data Distribution Across Partitions
- Data from the CSV file is partitioned and ingested into the memory of the worker nodes:
- Worker1:
- Partition1 contains Record1 and Record2.
- Worker2:
- Partition1 contains Record4 and Record5.
- Worker3:
- Partition2 contains Record6 and Record7.
- Worker1:
- This partitioning ensures the data is evenly distributed across worker nodes for balanced processing loads.
Task Activation
- Spark assigns tasks to process the data in each memory partition. However, only tasks with data to process are marked active, indicated as green in the diagram.
- Worker1: Two tasks are active, as both Partition1 and Partition2 contain data.
- Worker2: One task is active, as only Partition1 contains data.
- Worker3: One task is active, as only Partition2 contains data.
Through this structured approach, Spark ensures scalability and performance, even for massive datasets.
Different ways to connect to a Spark cluster
- Local Mode:
- Ideal for development and testing. Spark runs on a single machine using local threads.
- Specify
localorlocal[*]in the configuration, where[*]uses all available CPU cores.
- Standalone Mode:
- Spark’s built-in cluster manager.
- Connect to the master node using the format
spark://<hostname>:<port>in the configuration.
- YARN (Yet Another Resource Negotiator):
- Used in Hadoop-based environments.
- Set the deployment mode to
clusterorclientwhen configuring Spark.
- Apache Mesos:
- A general-purpose cluster manager.
- Provide the Mesos URL for the cluster in Spark’s configuration.
- Kubernetes:
- For deploying Spark applications in containers.
- Specify Kubernetes API server details in the configuration.
Each connection method fits specific needs, depending on the scale and type of application
“With a clear understanding of Spark’s architecture, we can now explore its powerful abstractions—RDDs and DataFrames—that operate seamlessly within this distributed framework. In the next article, we’ll uncover their internals and learn how to leverage them for efficient data processing.”
Author: Mohammad J Iqbal
