Apache Spark: Internals of RDDs and DataFrames with examples
Introduction:
In this installment of our Spark series, we dive deeper into the backbone of Spark: Resilient Distributed Datasets (RDDs) and DataFrames. Understanding their architecture, performance optimizations, and use cases will set you on a solid path toward mastering Spark for big data analytics.
1. RDDs vs. DataFrames: Architectures Uncovered
RDDs:
- Spark’s foundational abstraction for distributed data.
- Immutable and fault-tolerant collections that operate in parallel across clusters.
- Provide flexibility but require detailed control over data processing logic.
DataFrames:
- Higher-level abstraction built on RDDs, resembling relational tables with columns and rows.
- Optimized for structured data processing, leveraging Spark SQL for faster execution.
- Features lazy evaluation and Catalyst query optimization, ensuring performance and scalability.
When to Use:
- RDDs for low-level operations and custom transformations.
- DataFrames for structured data analytics with SQL-like simplicity.
Internals of a DataFrame?
A dataframe is both a data structure and an API, Spark’s dataframe API is used within Spark SQL, Spark Streaming, MLlib (for machine learning) and GraphX to manipulate graph based data structures within Spark. Using this unified API drastically simplifies access to those technologies. You will not have to learn an API for each sublibrary.
A dataframe is a set of records organized into named columns. It is equivalent to a table in a relational database or a ResultSet in Java. Fig below shows a full DataFrame with its schema and data
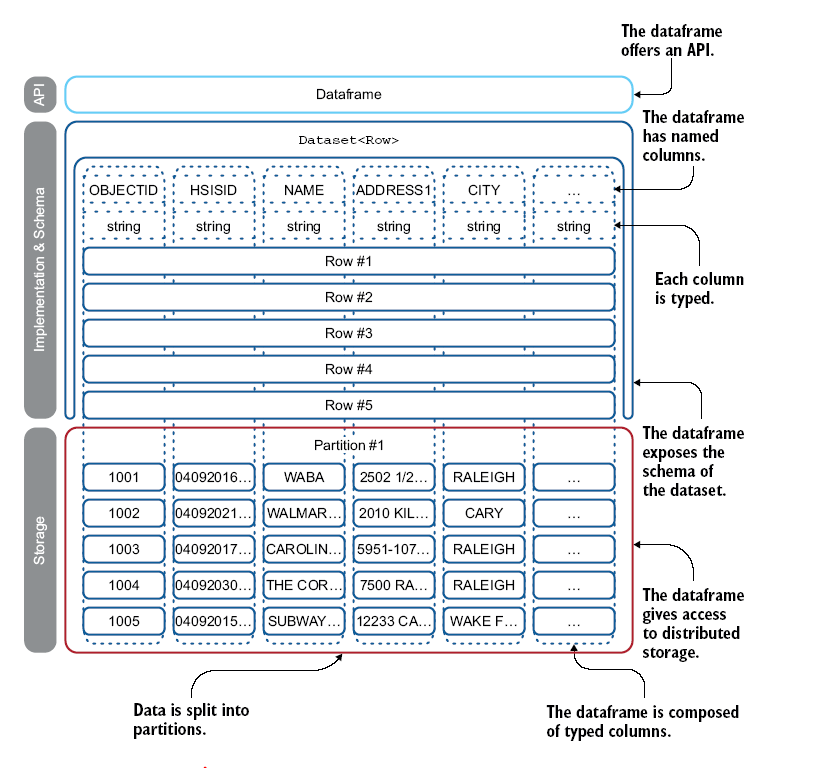
Dataframes can be constructed from a wide array of sources, such as files, databases, or custom data sources. The key concept of the dataframe is its API, which is available in Java, Python, Scala, and R.
**In Java, a dataframe is represented by a dataset of rows: Dataset